字典和集合
说起来,Python 就是包裹在一堆语法糖中的字典。
字典这个数据结构活跃在所有 Python 程序的背后,即便你的源码里并没有直接用到它
跟字典有关的内置函数都在 __builtins__.__dict__ 模块中。
正是因为字典��至关重要,Python 对它的实现做了高度优化,而 哈希表 / 哈希表 则是字典类型性能出众的根本原因。
模式匹配字典
def get_creators(record: dict) -> list:
match record:
case {'type': 'book', 'api': 2, 'authors': [*names]}: ❶
return names
case {'type': 'book', 'api': 1, 'author': name}: ❷
return [name]
case {'type': 'book'}: ❸
raise ValueError(f"Invalid 'book' record: {record!r}")
case {'type': 'movie', 'director': name}: ❹
return [name]
case _: ❺
raise ValueError(f'Invalid record: {record!r}')
- 匹配含有 'type': 'book', 'api' : 2,而且 'authors' 键映射一个序列的映射对象。以列表形式返回序列中的项。
- 匹配含有 'type': 'book', 'api' : 1,而且 'authors' 键映射任何对象的映射对象。以列表形式返回匹配的对象。
- 其他含有 'type': 'book' 的映射均无效,抛出 ValueError。
- 匹配含有 'type': 'movie',而且 'director' 映射单个对象的映射对象。以列表形式返回匹配的对象。
- 其他匹配对象均无效,抛出 ValueError。
注意,模式中键的顺序无关紧要
没有必要使用 **extra 匹配多出的键值对,倘若你想把多出的键值对捕获到一个 dict 中,可以在一个变量前面加上 ,不过必须放在模式最后。_ 是无效的,纯属画蛇添足。
>>> food = dict(category='ice cream', flavor='vanilla', cost=199)
>>> match food:
... case {'category': 'ice cream', **details}:
... print(f'Ice cream details: {details}')
...
Ice cream details: {'flavor': 'vanilla', 'cost': 199}
映射类型的标准 API
字典属于泛映射类型数据结构,不同于序列类型,字典总是由 key-value(键值对)构成。
collections.abc 中定义了 Mapping 和 MutableMapping 两个抽象基类,这些基类为 dict 等数据结构定义了形式接口。
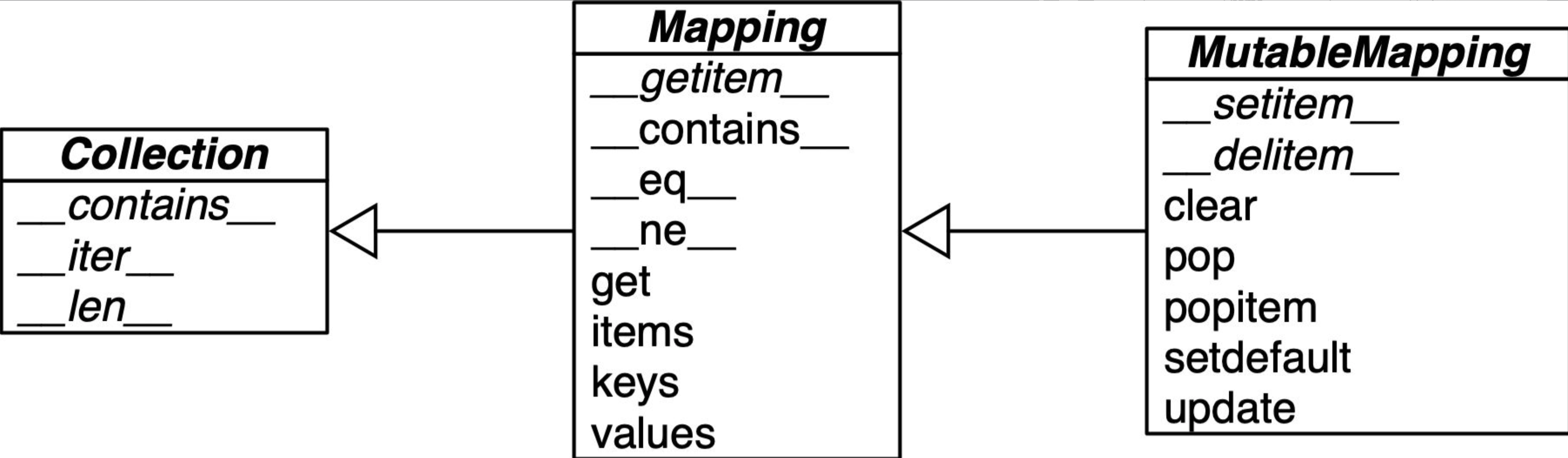
箭头由子类指向超类
这两个抽象基类的主要作用是确立映射对象的标准接口,并在需要广义上的映射对象时为 isinstance 提供测试标准。
>>> my_dict = {}
>>> isinstance(my_dict, abc.Mapping)
True
>>> isinstance(my_dict, abc.MutableMapping)
True
可哈希的数据类型
哈希函数的使用能够更快速的访问某一特定关键字对应的数据。
可哈希的定义:如果一个对象是可哈希的,那么在这个对象的生命周期中,它的哈希值是不变的。而且这个对象需要实现 __hash__() 方法和 __qe__() 方法,这样才能跟其他键做比较。
如果两个可哈希对象是相等的,那么它们的哈希值一定是一样的。
一些可哈希的数据类型
-
原子不可变数据类型(
str、bytes和数值类型)都是可哈希类型 -
frozenset也是可哈希的,因为根据其定义,frozenset里只能容纳可哈希类型。 -
tuple的话,只有当一个元组包含的所有元素都是可哈希类型的情况下,它才是可哈希的。比如下面例子里的tt、tl和tf -
一般来讲用户自定义的类型的对象都是可哈希的,哈希值就是它们的
id()函数的返回值,所以所有这些对象在比较的时候都是不相等的。
>>> tt = (1, 2, (30, 40))
>>> hash(tt)
8027212646858338501
>>> tl = (1, 2, [30, 40])
>>> hash(tl)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> tf = (1, 2, frozenset([30, 40]))
>>> hash(tf)
-4118419923444501110
根据这些定义,字典提供了 很多种构造方法,“Built-in Types”
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
其他细节
- 默认情况下,用户定义的类型是可哈希的,因为自定义类型的哈希码取自 id(),而且继承自 object 类的
__eq__()方法只不过是比较对象 ID。如果自己实现了__eq__()方法,根据对象的内部状态进行比较,那么仅当__hash__()方法始终返回同一个哈希码时,对象才是可哈希的。- 实践中,这要求
__eq__()和__hash__()只考虑在对象的生命周期内始终不变的实例属性。
- 实践中,这要求
- 一个对象的哈希码根据所用的 Python 版本和设备架构有所不同。如果出于安全考量而在哈希计算过程中加盐,那么哈希码也会发生变化。正确实现的对象,其哈希码在一个 Python 进程内保持不变。
常见的映射方法
| dict | defaultdict | OrderedDict | ||
|---|---|---|---|---|
d.clear() | • | • | • | 移除所有元素 |
d.__contains__(k) | • | • | • | 检查 k 是否在 d 中 |
d.copy() | • | • | • | 浅复制 |
d.__copy__() | • | 用于支持 copy.copy | ||
d.default_factory | • | 在 __missing__ 函数中被调用的函数,用以给未找到的元素设置值 * | ||
d.__delitem__(k) | • | • | • | del d[k],移除键为 k 的元素 |
d.fromkeys(it, [initial]) | • | • | • | 将迭代器 it 里的元素设置为映射里的键,如果有 initial 参数,就把它作为这些键对应的值(默认是 None) |
d.get(k, [default]) | • | • | • | 返回键 k 对应的值,如果字典里没有键 k,则返回 None 或者 default |
d.__getitem__(k) | • | • | • | 让字典 d 能用 d[k] 的形式返回键 k 对应的值 |
d.items() | • | • | • | 返回 d 里所有的键值对 |
d.__iter__() | • | • | • | 获取键的迭代器 |
d.keys() | • | • | • | 获取所有的键 |
d.__len__() | • | • | • | 可以用 len(d) 的形式得到字典里键值�对的数量 |
d.__missing__(k) | • | 当 __getitem__ 找不到对应键的时候,这个方法会被调用 | ||
d.move_to_end(k, [last]) | • | 把键为 k 的元素移动到最靠前或者最靠后的位置(last 的默认值是 True) | ||
d.pop(k, [defaul] | • | • | • | 返回键 k 所对应的值,然后移除这个键值对。如果没有这个键,返回 None 或者 defaul |
d.popitem() | • | • | • | 随机返回一个键值对并从字典里移除它# |
d.__reversed__() | • | 返回倒序的键的迭代器 | ||
d.setdefault(k, [default]) | • | • | • | 若字典里有键 k,则把它对应的值设置为 default,然后返回这个值;若无,则让 d[k] = default,然后返回 default |
d.__setitem__(k, v) | • | • | • | 实现 d[k] = v 操作,把 k 对应的值设为 v |
d.update(m, [**kargs]) | • | • | • | m 可以是映射或者键值对迭代器,用来更新 d 里对应的条目 |
d.values() | • | • | • | 返回字典里的所有值 |
映射的弹性键查询
get() & setdefault()
get() 能够规避对 dict 中某一个 key 赋值时,由于 key 不存在于 dict 中导致的 keyError。但是利用 get() 方法处理这种情况需要经过多次键查询操作(get() 是一次,然后赋值又是一次,并且还需要创建临时变量用于存放取得的值以及对值的操作)
setdefault() 则可以一步完成上述工作
my_dict.get(key, [])
my_dict.setdefault(key, []) # 更高效
# ----------------------------------
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
# 等同于
my_dict.setdefault(key, []).append(new_value)
但有时候为了方便起见,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。有两个途径能帮我们达到这个目的:
- 一个是通过
defaultdict这个类型而不是普通的dict - 另一个是给自己定义一个
dict的子类,然后在子类中实现__missing__方法。
下面将介绍这两种方法。
defaultdict
有些时候,希望某个键不存在于映射中也会返回一个默认值,collections.defaultdict 实现了 __missing__ 方法,用于应对这种需求。
defaultdict 会按照如下步骤处理映射类型中不存在的键
- 调用定义时传入的方法参数,用以创建一个新的对象(例如,定义时传入 list 方法,则会调用
list()方法创建一个新 list) - 将新对象作为值,构建键值对并记录到原字典中
- 返回新创建的键值对的值的引用
# 把 list 构造方法作为 default_factory 来创建一个 defaultdict
my_dict = collections.defaultdict(list)
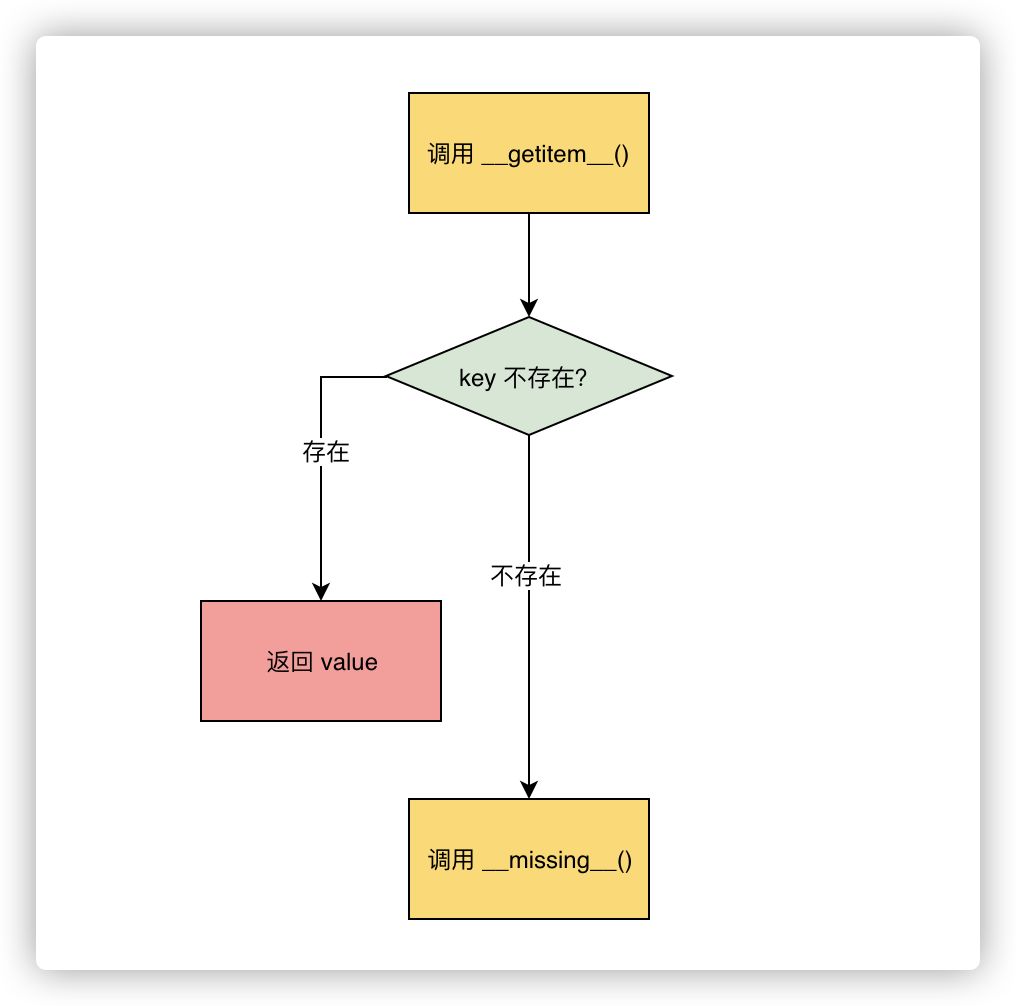
defaultdict 依赖 default_factory 方法实现上述操作,值得注意的是,defaultfactory 仅会在 __getitem__ 中被调用;对于一个不存在于字典中的键 "new_key",若直接用 get() 函数获取其对应的值则会返回 None。
__getitem__ 并不会直接调用 default_factory,而是按照如下流程进行调用:
- 执行
defaultdict["new_key"],希望获得 "new_key" 对应的值 - 调用
__getitem__()方法,结果没有在键列表中查询到 "new_key" - 调用
__missing__()方法,处理未知键 "new_key" - 调用
default_factory()方法,赋予 "new_key" 默认值
上述流程中最为关键的是 __missing__() 方法的实现。它会在 defaultdict 遇到找不到的键的时候调用 default_factory。
自定义 __missing__
实际上,对于自定义的映射数据类型,若想处理未知键的查询和创建任务,也仅需要实现 __missing__() 方法就好。
class TestDict(dict):
# 其他代码,省略
def __missing__(self, key):
print("call __missing__")
# 新增 key
self[key] = "default"
# 返回该项
return "default"
如果要自定义一个映射类型,更合适的策略其实是继承
collections.UserDict类(示例 3-8 就是如此)。这里我们从dict继承,只是为了演示__missing__是如何被dict.__getitem__调用的。
字典的变种
dict 类型是最常用的映射类型,defaultdict 和 OrderedDict 则是 dict 的变种,这两个类型支持一些特殊的用法。此外还有如 ChainMap(可容纳多个映射对象并在进行键查找时,在所有的映射对象中进行查找)、Counter(具有计数器功能,相当适用于计数任务)、UserDict(开箱即用的自定义映射类型基类)等
总的来说,这些变种均具有 dict 具有的功能,此外还为了应对不同的应用场合提供了更为丰富的功能。
collections.defaultdict
defaultdict 对未知键提供了特殊支持,当传入字典中不存在的键获取数据时,dict 会直接报错,而 defaultdict 则会默认为这个新键创建对应的键值对(在建立字典的时候非常非常非常好用,之前都是首先用 if 判断字典中是否存在该键,然后根据判断结果创建或者修改键值对)
collections.OrderedDict
OrderedDict 则对顺序提供了额外支持,普通的 dict 并不会记录键值对的顺序,或者说 dict 中的键值对都是无序的,但是 OrderedDict 则提供了额外的键值对顺序功能支持,支持类似于先入先出的功能。
OrderedDict 的 popitem 方法默认删除并返回的是字典里的最后一个元素,但是如果像 my_odict.popitem(last=False) 这样调用它,那么它删除并返回第一个被添加进去的元素。
collections.ChainMap
详见 https://www.cnblogs.com/mangmangbiluo/p/9882097.html
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文。
from collections import ChainMapa = {"x":1, "z":3}
b = {"y":2, "z":4}
c = ChainMap(a,b)
print(c)
print("x: {}, y: {}, z: {}".format(c["x"], c["y"], c["z"]))
输出:
ChainMap({'x': 1, 'z': 3}, {'y': 2, 'z': 4})
x: 1, y: 2, z: 3
[Finished in 0.1s]
这是 ChainMap 最基本的使用,可以用来合并两个或者更多个字典,当查询的时候,从前往后依次查询。
从原理上面讲,ChainMap 实际上是把放入的字典存储在一个队列中,当进行字典的增加删除等操作只会在第一个字典上进行,当进行查找的时候会依次查找
有一个注意点就是当对 ChainMap 进行修改的时候总是只会对第一个字典进行修改
In [6]: a = {"x":1, "z":3}
In [7]: b = {"y":2, "z":4}
In [8]: c = ChainMap(a, b)
In [9]: c
Out[9]: ChainMap({'z': 3, 'x': 1}, {'z': 4, 'y': 2})
In [10]: c["z"]
Out[10]: 3
In [11]: c["z"] = 4
In [12]: c
Out[12]: ChainMap({'z': 4, 'x': 1}, {'z': 4, 'y': 2})
In [13]: c.pop('z')
Out[13]: 4
In [14]: c
Out[14]: ChainMap({'x': 1}, {'z': 4, 'y': 2})
In [15]: del c["y"]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
......
KeyError: "Key not found in the first mapping: 'y'"
collections.Counter
这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。
所以这个类型可以用来给可哈希表对象计数,或者是当成多重集来用——多重集合就是集合里的元素可以出现不止一次。
Counter 实现了 + 和 - 运算符用来合并记录,还有像 most_common([n]) 这类很有用的方法。most_common([n]) 会按照次序返回映射里最常见的 n 个键和它们的计数
下面的小例子利用 Counter 来计算单词中各个字母出现的次数:
>>> ct = collections.Counter('abracadabra')
>>> ct
Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.update('aaaaazzz')
>>> ct
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.most_common(2)
[('a', 10), ('z', 3)]
UserDict
这个类其实就是把标准 dict 用纯 Python 又实现了一遍。
跟 OrderedDict、ChainMap 和 Counter 这些开箱即用的类型不同,UserDict 是让用户继承写子类的。
子类化 UserDict
而更倾向于从 UserDict 而不是从 dict 继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题
另外一个值得注意的地方是,UserDict 并不是 dict 的子类,但是 UserDict 有一个叫作 data 的属性,是 dict 的实例,这个属性实际上是 UserDict 最终存储数据的地方。这样做的好处是,比起示例 3-7,UserDict 的子类就能在实现 __setitem__ 的时候避免不必要的递归,也可以让 __contains__ 里的代码更简洁。
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item
不可变的映射类型
从 Python 3.3 开始,types 模块中引入了一个封装类名叫 MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。
虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
>>> from types import MappingProxyType
>>> d = {1:'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'})
>>> d_proxy[1] # d 中的内容可以通过 d_proxy 看到
'A'
>>> d_proxy[2] = 'x' # 但是通过 d_proxy 并不能做任何修改
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
>>> d[2] = 'B'
>>> d_proxy # d_proxy 是动态的,也就是说对 d 所做的任何改动都会反馈到它上面
mappingproxy({1: 'A', 2: 'B'})
>>> d_proxy[2]
'B'
集合
集合在 Python 中是一个较新的概念,其描述了 唯一 对象的集合。集合有如下特点:
- 元素的唯一性:集合中不会有两个一样的对象(这里的唯一性指的是 hash 的唯一性)
- 集合中的元素必须是可哈希的,但是
set本身是不可哈希的,set类型本身是不可哈希的,但是frozenset可以。因此可以创建一个包含不同frozenset的set。 - 集合允许各种基于集合的二元运算,例如交集、并集以及差集
a | b返回的是它们的合集,a & b得到的是交集��,而a - b得到的是差集。
集合的字面量
>>> s = {1}
>>> type(s)
<class 'set'>
>>> s
{1}
>>> s.pop()
1
>>> s
set()
像 {1, 2, 3} 这种字面量句法相比于构造方法(set([1, 2, 3]))要更快且更易读。后者的速度要慢一些,因为 Python 必须先从 set 这个名字来查询构造方法,然后新建一个列表,最后再把这个列表传入到构造方法里。但是如果是像 {1, 2, 3} 这样的字面量,Python 会利用一个专门的叫作 BUILD_SET 的字节码来创建集合。
用 dis.dis(反汇编函数)来看看两个方法的字节码的不同:
>>> from dis import dis
>>> dis('{1}') ➊
1 0 LOAD_CONST 0 (1)
3 BUILD_SET 1 ➋
6 RETURN_VALUE
>>> dis('set([1])') ➌
1 0 LOAD_NAME 0 (set) ➍
3 LOAD_CONST 0 (1)
6 BUILD_LIST 1
9 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
12 RETURN_VALUE
➊ 检查 {1} 字面量背后的字节码。
➋ 特殊的字节码 BUILD_SET 几乎完成了所有的工作。
➌ set([1]) 的字节码。
➍ 3 种不同的操作代替了上面的 BUILD_SET:LOAD_NAME、BUILD_LIST 和 CALL_FUNCTION。
集合推导
>>> from unicodedata import name # 从 unicodedata 模块里导入 name 函数,用以获取字符的名字
>>> {chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i),'')}
{'§', '=', '¢', '#', '¤', '<', '¥', 'μ', '×', '$', '¶', '£', '©',
'°', '+', '÷', '±', '>', '¬', '®', '%'}
dict 和 set 的背后
哈希表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构教材中,哈希表里的单元通常叫作表元(bucket)。在 dict 的哈希表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的哈希表会被复制到一个更大的空间里面。
如果要把一个对象放入哈希表,那么首先要计算这个元素键的 哈希值。Python 中可以用 hash() 方法来做这件事情。
哈希值和相等性
内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义对象调用 hash() 的话,实际上运行的是自定义的 __hash__。
如果两个对象在比较的时候是相等的,那它们的哈希值必须相等,否则哈希表就��不能正常运行了。例如,如果 1 == 1.0 为真,那么 hash(1) == hash(1.0) 也必须为真,但其实这两个数字(整型和浮点)的内部结构是完全不一样的
为了让哈希值能够胜任哈希表索引这一角色,它们必须在索引空间中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等的对象,它们哈希值的差别应该越大。
总结一下,一个可哈希的对象必须满足以下要求。
- 支持
hash()函数,并且通过__hash__()方法所得到的哈希值是不变的。 - 支持通过
__eq__()方法来检测相等性。 - 若
a == b为真,则hash(a) == hash(b)也为真。
所有由用户自定义的对象默认都是可哈希的,因为它们的哈希值由 id() 来获取,而且它们都是不相等的
如果你实现了一个类的
__eq__方法,并且希望它是可哈希的,那么它一定要有个恰当的__hash__方法,保证在a == b为真的情况下hash(a) == hash(b)也必定为真。否则就会破坏恒定的哈希表算法,导致由这些对象所组成的字典和集合完全失去可靠性,这个后果是非常可怕的。另一方面,如果一个含有自定义的
__eq__依赖的类处于可变的状态,那就不要在这个类中实现__hash__方法,因为它的实例是不可哈希的。
一个例子
在 32 位的 Python 中,1、1.0001、1.0002 和 1.0003 这几个数的哈希值的二进制表达对比(上下两个二进制间不同的位被 ! 高亮出来,表格的最右列显示了有多少位不相同)
32-bit Python build
1 00000000000000000000000000000001
!= 0
1.0 00000000000000000000000000000001
------------------------------------------------
1.0 00000000000000000000000000000001
! !!! ! !! ! ! ! ! !! !!! != 16
1.0001 00101110101101010000101011011101
------------------------------------------------
1.0001 00101110101101010000101011011101
!!! !!!! !!!!! !!!!! !! ! != 20
1.0002 01011101011010100001010110111001
------------------------------------------------
1.0002 01011101011010100001010110111001
! ! ! !!! ! ! !! ! ! ! !!!! != 17
1.0003 00001100000111110010000010010110
------------------------------------------------
从 Python 3.3 开始,
str、bytes和datetime对象的哈希值计算过程中多了随机的“加盐”这一步。所加盐值是 Python 进程内的一个常量,但是每次启动 Python 解释器都会生成一个不同的盐值。随机盐值的加入是为了防止 DOS 攻击而采取的一种安全措施。
哈希表算法
为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key) 来计算 search_key 的 哈希值,把这�个值最低的几位数字当作偏移量,在哈希表里查找表元(具体取几位,得看当前哈希表的大小)。若找到的表元是空的,则抛出 KeyError 异常。若不是空的,则表元里会有一对 found_key:found_value。这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value。
如果 search_key 和 found_key 不匹配的话,这种情况称为 哈希冲突。发生这种情况是因为,哈希表所做的其实是把随机的元素映射到只有几位的数字上,而哈希表本身的索引又只依赖于这个数字的一部分。为了解决哈希冲突,算法会在哈希值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元;若这次找到的表元是空的,则同样抛出 KeyError;若非空,或者键匹配,则返回这个值;或者又发现了哈希冲突,则重复以上的步骤。
总结一下:
- 计算键的哈希值
- 使用哈希值的一部分来定位哈希表中的一个表元
- 判断表元是否为空
- 若为空,抛出 KeyError
- 若不为空,执行第 4 步
- 检查是否是期望的元素
- 若是期望的元素,返回表元中的值
- 若不是期望的元素,执行第 5 步
- 发生冲突,使用哈希值的另一部分来定位哈希表中的另一行,并返回第 3 步
添加新元素和更新现有键值的操作几乎跟查找一样。只不过对于前者,在发现空表元的时候会放入一个新元素;对于后者,在找到相对应的表元后,原表里的值对象会被替换成新值。。此外,为了保证哈希表的稀疏性,当元素数量增添到一定阈值时,Python 会自动将这个哈希表复制到更大的空间中以避免冲突。
一些特点
字典在内存上的开销巨大
由于字典使用了哈希表,而哈希表又必须是稀疏的,这导致它在空间上的效率低下。
举例而言,如果你需要存放数量巨大的记录,那么放在 由元组或是具名元组构成的列表 中会是比较好的选择;最好不要根据 JSON 的风格,然后用字典组成的列表来存放这些记录。
用元组取代字典就能节省空间的原因有两个:其一是避免了哈希表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。
在用户自定义的类型中,
__slots__属性可以改变实例属性的存储方式,由dict变成tuple
总结
- 正是由于 dict 和 set 使用哈希表来进行数据存储,在进行元素查找时不需要对所有元素进行遍历,这使得搜索特定元素的效率大大提高。
- 并且由于稀疏性,查找时间不会随着 dict 和 set 中元素数量的增加而线性增长。
- 由于使用哈希表进行存储,dict 和 set 中的元素也没有固定的顺序,在添加新元素时原有的顺序可能会被改变
- dict 和 set 使用哈希表进行数据存储,因此这两个数据类型要求元素时可哈希的。
- 即,在 Python 中某元素必须支持
__hash__()函数,并且通过__hash__()函数取得的哈希值在生命周期中不发生变化。 - 此外,Python 还要求可哈希的元素支持
__eq__()方法以判断相等性。这些条件使得不是所有的对象均可以作为 dict 的键或者 set 的元素。
- 即,在 Python 中某元素必须支持
- 与 2 类似,由于添加元素后很可能改变原有的顺序,因此在 dict 和 set 中讨论元素的顺序没有意义,除非使用类似于 OrderedDict 这样的特殊类型。
- 由于元素的顺序不确定,在循环迭代 dict 或者 set 的同时删增元素可能会导致跳过某些元素。
- 若使用
.keys()、.values()以及.items()等函数对 dict 进行循环迭代,Python3 中这些方法返回的字典视图具有动态的特性。即,循环迭代过程中对 dict 的改变会实时反馈到循环条件上,这显然会导致不可预测的错误。
- 若使用
- dict 和 set 是空间换时间的典型例子。哈希表需要保证稀疏性以尽可能避免冲突
- 因此,相较于 list,dict 和 set 需要维护更大的内存空间以保证哈希表的稀疏性
其他
- 像
k in my_dict.keys()这种操作在 Python 3 中是很快的,而且即便映射类型对象很庞大也没关系。这是因为dict.keys()的返回值是一个 “视图”。- 视图就像一个集合,而且跟字典类似的是,在视图里查找一个元素的速度很快。Python 2 的
dict.keys()返回的是个列表,因此虽然上面的方法仍然是正确的,它在处理体积大的对象的时候效率不会太高,因为k in my_list操作需要扫描整个列表。
- 视图就像一个集合,而且跟字典类似的是,在视图里查找一个元素的速度很快。Python 2 的
- CPython 的实现细节里有一条是:如果有一个整型对象,而且它能被存进一个机器字中,那么它的哈希值就是它本身的值
- 在哈希冲突的情况下,用 C 语言写的用来打乱哈希值位的算法的名字很有意思,叫
perturb。详见 CPython 源码里的dictobject.c(https://hg.python.org/cpython/file/tip/Objects/dictobject.c) - PHP 和 Ruby 的哈希语法借鉴了 Perl,它们都用
=>作为键和值的连接。JavaScript 则从 Python 那儿偷师,使用了:。而 JSON 又从 JavaScript 发展而来,它的语法正好是 Python 句法的子集。因此,除了在true、false和null这几个值的拼写上有出入之外,JSON 和 Python 是完全兼容的。于是,现在大家用来交换数据的格式全是 Python 的dict和list。 - 字典的拆包允许键重复,后面的键覆盖前面的键